
Nvidiaのアーム型CPU「Grace」が登場、x86サーバーの10倍の性能を主張
Nvidia社は、ArmベースのGrace CPUアーキテクチャを発表し、AIおよびHPCワークロードにおいて、現在の最速サーバーの10倍のパフォーマンスを実現するとします。新しいチップは、まもなく2つの新しいAIスーパーコンピュータに搭載される予定で、不特定多数の「次世代」Arm Neoverse CPUコアと、500GBpsのスループットを発揮するLPDDR5xメモリを組み合わせて搭載し、さらに最先端デバイス用の不特定多数のGPUへの900 GBpsのNVLink接続を備えています。
また、Nvidiaは、2025年に登場する「Grace Next」CPUと、2024年半ばに登場する新しい「Ampere Next Next」GPUの新しいロードマップを公開しました(下図)。NvidiaによるARM社の買収は、現在も世界各国の規制機関を通過中であり、NvidiaブランドのArmベースのCPUが登場するのではないかという憶測を呼んでいます。Nvidia社のCEOであるJensen Huang氏は、その可能性を認めています。Grace CPUアーキテクチャの最初の製品は、私たちが慣れ親しんでいるソケット型フォームファクターの汎用デザインではありませんが(代わりに、チップはGPUとともにマザーボードに搭載されます)、Nvidia社が独自のArmベースのデータセンター用CPUの展開に真剣に取り組んでいることは明らかです。
Nvidiaはまだコア数や周波数の情報を公開していませんが、Grace CPUが市場に投入されるのが2023年初頭であることを考えれば、まったく不思議ではありません。Nvidiaは、これらのコアが次世代のArm Neoverseコアであることを明らかにしました。Arm社が現在公開しているロードマップ(以下のスライド)によれば、おそらくV1プラットフォームの「Zeus」コアであり、電力とダイ面積を犠牲にして最大のパフォーマンスを得るように最適化されています。

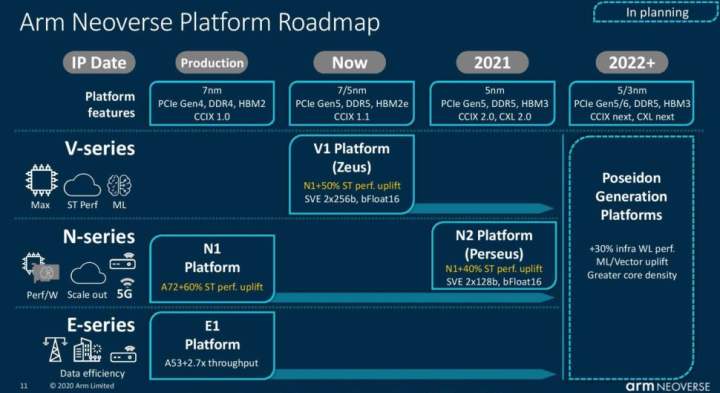
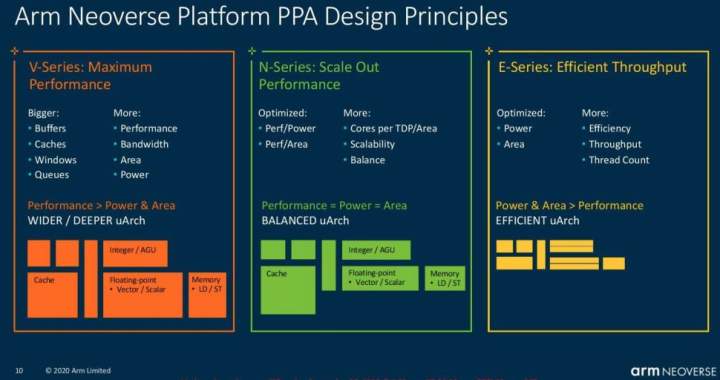
Zeusコアを搭載したチップは、7nmまたは5nmのいずれかのバージョンで登場し、現在のArm N1コアに比べてIPCが50%向上します。Arm V1プラットフォームは、PCIe 5.0、DDR5、HBM2eまたはHBM3、そしてCCIX 1.1インターコネクトなどの最新のハイエンド技術をすべて対応します。少なくとも今のところ、NvidiaはCPUとGPUの接続にCCIXではなく独自のNVLinkを利用しているようです。
Nvidiaは、Grace CPUがSPECrate_2017_int_baseベンチマークで300以上の予測スコアを出すなど、十分なパフォーマンスを発揮するとします。Nvidiaは、1つのDGXシステムに8つのGPUを搭載した場合、SPECrate_2017_int_baseのスコアが2,400になるようにリニアにスケールアップすると主張します。現在のDGXの最高スコアが450であることと比較しても、素晴らしいことです。
データセンターにおける現在のパフォーマンスリーダーであるAMDのEPYC Milanチップは、SPECの結果が382~424となっており、GraceのシングルCPUは、AMDの前世代の64コアRomeチップと同等の性能を持っています。Nvidiaが既存のサーバーと比較して「10倍」のパフォーマンスを謳っていることから、同社はGPU駆動のワークロードを指していると考えられます。
Nvidia Grace CPUの最初のバージョンは、BGAパッケージとして実装され(つまり、従来のx86サーバーチップのようなソケット化された部品ではない)、LPDDR5xメモリが8パッケージ搭載されているようです。Nvidiaによれば、LPDDR5x ECCメモリは、標準的なDDR4メモリサブシステムに比べて、2倍の帯域幅と10倍の電力効率を提供します。
Nvidiaの次世代NVLinkは、まだ詳細をあまり公開していませんが、チップと隣接するCPUを900 GBpsの転送速度(14倍)で接続し、従来のCPUからGPUへのデータ転送速度を30倍も上回っています。また、CPU間のデータ転送速度も従来の2倍となり、CPU、GPU、システムメモリーなど様々な計算要素間の最適ではないデータ転送速度の束縛から解放されるとします。
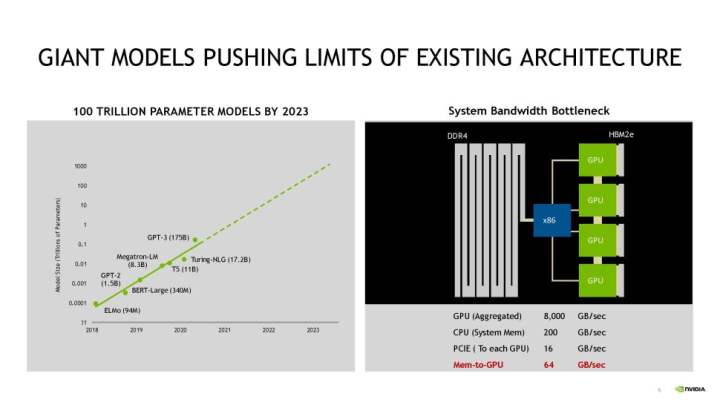

上の図は、最新のシステムでGPUに十分な帯域幅を供給する上でのNvidiaの主要な問題を示しています。最初のスライドは、x86 CPU駆動システムにおけるメモリからGPUへの帯域幅の制限(64GBps)を示しています。PCIeスループットの制限(16GBps)は、低いスループットをさらに悪化させ、最終的にGPUが完全に利用できるシステムメモリの量を制限します。2枚目のスライドは、Grace CPUを使用した場合のスループットを示します。4本のNVLinkでスループットは500 GBpsに向上し、メモリからGPUへのスループットは30倍の2,000 GBpsに達します。
NVLinkの実装では、キャッシュコヒーレンシーも実現しており、システムメモリとGPUメモリ(LPDDR5xおよびHBM)を同じメモリアドレス空間に配置することで、プログラミングを容易にします。また、キャッシュコヒーレンシーは、CPUとGPU間のデータ移動を減らし、性能と効率の両方を向上させます。今回の機能追加により、エヌビディアは、AMDがエクサスケール・スーパーコンピュータ「Frontier」においてEPYC CPUとRadeon Instinct GPUを組み合わせたのと同様の機能を提供することができます。また、インテルが同じく世界最先端のエクサスケール・スーパーコンピュータ「Aurora」において、Ponte VecchioグラフィックカードとSapphire Rapids CPUを組み合わせたのと同様の機能を提供することができます。
エヌビディアは、この組み合わせにより、世界最大の自然言語AIモデル「GPT-3」を、2.8AIエクサフロップスの「Selene」(現在の世界最速AIスーパーコンピューター)で学習させる際の時間を、14日から2日に短縮することができます。
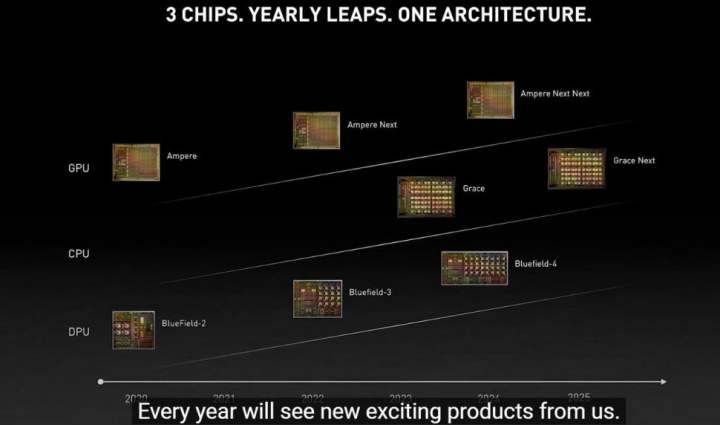
Nvidiaは、GPU、CPU(Armおよびx86)、DPUのすべてを共存させ、安定したサイクルで進化させることで、今後数年間の更新サイクルを決定するという、新しいロードマップも明らかにしました。Huang氏によると、x86が1年、Armが次の年というように、各アーキテクチャを2年ごとに進化させ、その間に「キッカー」と呼ばれる世代が登場する可能性があるとのことです。
なお、NvidiaはCPUアーキテクチャ「Grace」を、著名なコンピュータ科学者であるグレース・ホッパーにちなんで命名しました。Nvidiaは、チップレットベースのHopper GPUの開発にも取り組んでいると噂されており、CPUとGPUのコードネームの組み合わせは興味深いものになりそうです。




米国エネルギー省のロスアラモス国立研究所は、Graceを搭載したスーパーコンピュータを構築する予定です。このシステムは、HPE社(旧Cray社と呼ばれていた部門)によって構築され、2023年に稼働する予定ですが、DOEはこの新システムの詳細をあまり公表していません。
Grace CPUは、エヌビディアが世界最強のAI対応スーパーコンピューターと謳う、スイス国立計算センター(CSCS)に配備されるAlpsシステムにも搭載されます。アルプスは、2023年の稼働開始時には、主にヨーロッパの科学者や研究者向けに、気候、分子力学、計算流体力学などのワークロードを提供します。
NvidiaがArmの買収に関心を持っていることを考えると、同社が既存のArmの顧客との関係を広げていくことを期待するのは当然でしょう。これは、AWSがArmアーキテクチャーを採用したことで、クラウドワークロードへの導入が拡大したことを意味します。Nvidia社の協力により、同社のGPUからAndroidゲームへのストリーミングゲームが可能になるとともに、AI推論のワークロードを、すべてAWSのクラウドから実現することができます。それらの取り組みは、2021年の後半に結実する予定です。
関連ニュース

Tom's Hardware・2022-06-03

Tom's Hardware・2022-06-03

Tom's Hardware・2022-06-03

Tom's Hardware・2022-06-01

Tom's Hardware・2022-05-31

Tom's Hardware・2022-05-31
みんなの自作PC
![[70万]RTX3080 12900K 搭載エヴァコラボゲーミングPC(でも正直70万あったら3090Ti乗せてもおさまるから見た目追い求める人以外は3090Ti買ったほうがいい)](https://cdn.jisaku.com/upload/7c/noRgcuZik3ymkn/2400.webp)
