
AMD、2025年までにチップの効率を30倍にすることを目指す
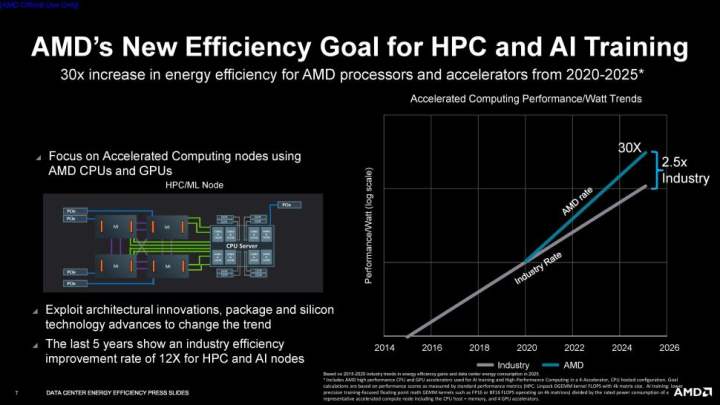
AMDは本日、2025年までにEPYC CPUおよびInstinct GPUアクセラレーターのエネルギー効率を30倍にするという、極めて野心的な目標を発表しました。この目標は、一般的な業界全体の効率改善を150%上回るものであり、AMD自身も目標がいかに高いものであるかを理解しています。
AMDの新たな取り組みは、2014年から2020年まで実施された「20x25」イニシアティブに続くもので、同社のノートブック・チップのエネルギー効率を25倍に向上させました(注目すべきは、これにはプロセッサーのアイドル時と負荷時の両方の効率が含まれていたことです)。
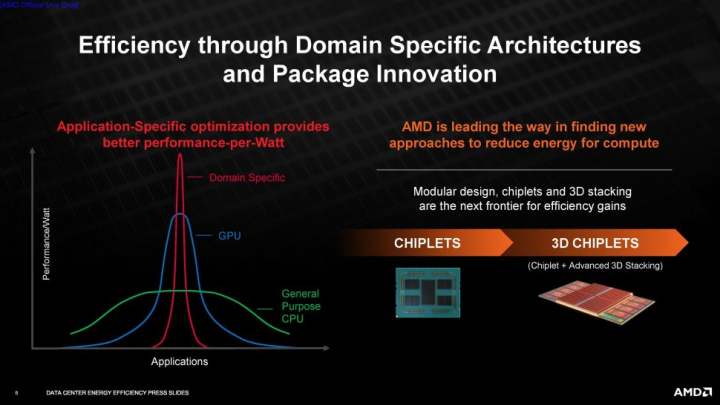
今回のAMDの新しい取り組みは、特にAIとHPCのワークロードに焦点を当てており、同社の目標は将来のハードウェア設計計画を示唆していると考えられます。例えば、AMDは、新たな消費電力目標に向けてパフォーマンスを向上させることを計画していますが、単にパフォーマンスの問題にダイエリアを増やす(すなわち、チップを大きくする)ことを望んでいるわけではありません。その代わりに、パフォーマンスとワットあたりのパフォーマンスを同時に向上させ、パフォーマンスと効率の両方を向上させることを考えています。
どのような目標であっても、AMDはその目標に向けた進捗状況を測定する方法を持たなければなりません。同社がAIとHPCワークロードにおけるパフォーマンスに焦点を当てていることを考慮して、AMDはFP16またはBF16 FLOPS(Linpack DGEMMカーネルFLOPS、4kマトリクスサイズ)、つまりAIトレーニングワークロードに一般的に使用されるデータタイプを使用することにしました。
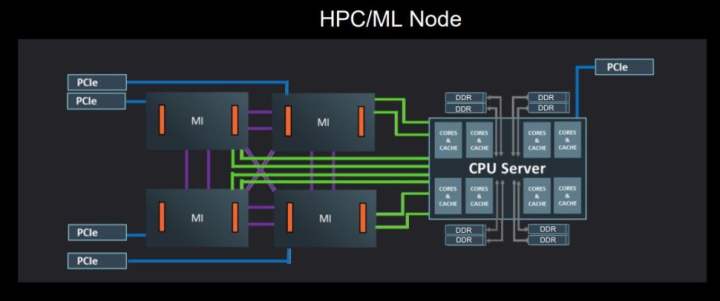
AMDは、4つのMI60 GPUと1つのEPYC CPU(不特定多数のモデル)を搭載した既存のシステム(コンピュートノード)の性能を集計し、ベースラインとなる性能測定値を設定しました。これをベースラインの"2020システム"と定義します。AMDは、同じ数のGPUとCPUを搭載した新世代のサーバーノードでマイルストーンを計測します。
ここで理解しておきたいのは、AMDは、BF16やFP16データタイプの固定関数(ハードウェアレベル)アクセラレーションを追加するだけで、目標に向かって大きくジャンプすることができ、比較的"簡単に"大きな性能や効率の向上を得ることができるということです。例えば、MI60はFP16をサポートしますが、BF16はサポートしません。


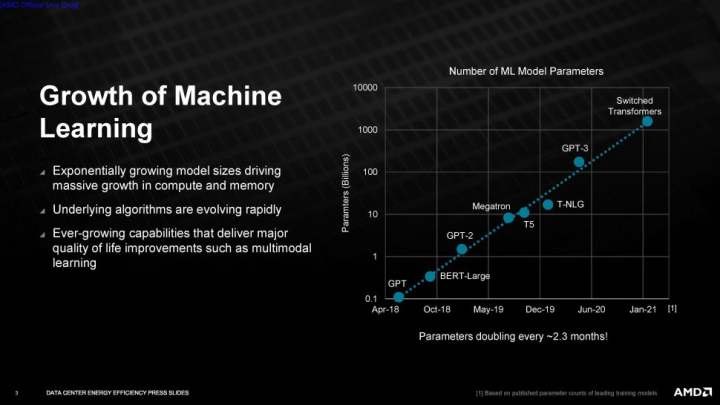
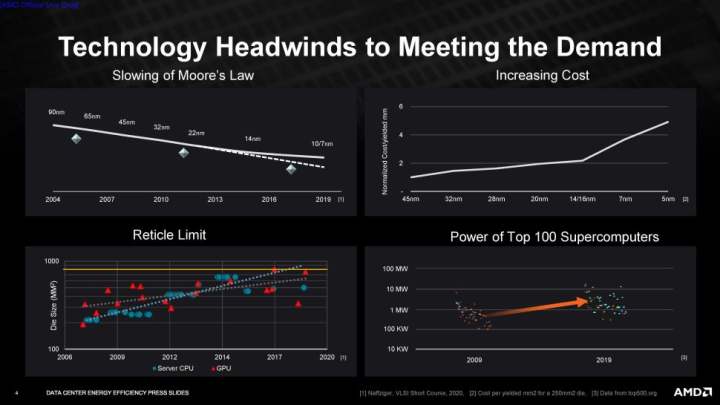
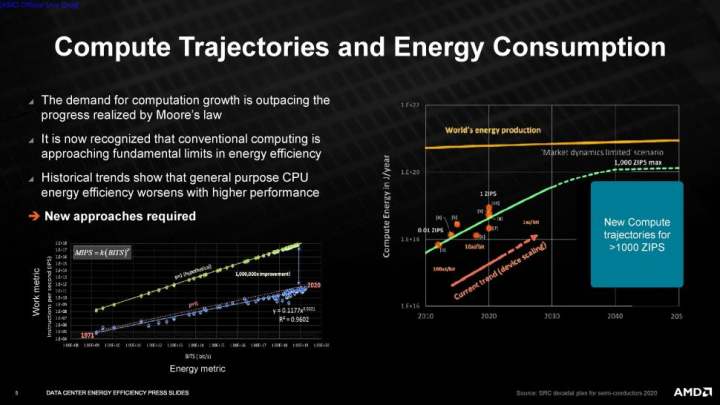

AMDは、目標を達成するためにハードウェアとソフトウェアの両方の最適化に頼ると語りましたが、その過程で期待できるハードウェアアクセラレーションの種類については言及しませんでした。この追加だけでも、対象となるワークロードでのパフォーマンスが大幅に向上する可能性があります。さらに、ソフトウェアの最適化は、既存のハードウェアで大規模な改善をもたらすことが常であるため、AMDは目標を達成するためにいくつかの選択肢を持つことになります。
ノートブックの効率性を向上させるというAMDの前回の目標とは異なり、AMDはテスト手法にアイドル時の電力消費量の測定を取り入れていません。その代わりに、ワークロードの一般的な使用率(約90%)にデータセンターのPUE(Power Usage Effectiveness:データセンターの効率性を示す指標)を乗じた値を使用します。AMDによれば、これによりワット当たりの電力量の指標に近い値が得られるとのことですが、AMDが計算に使用する最終的な計算式は見ていません。
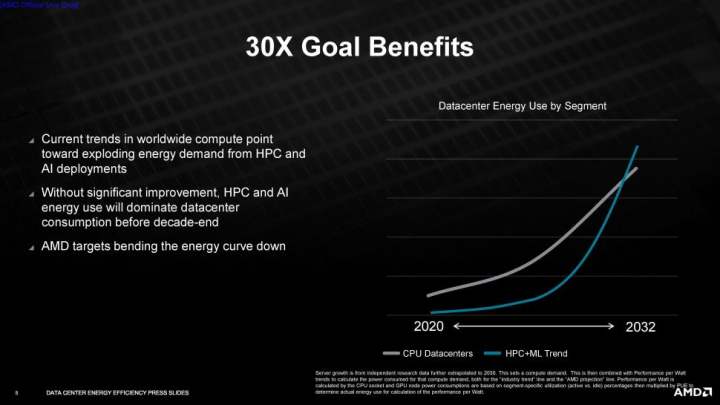
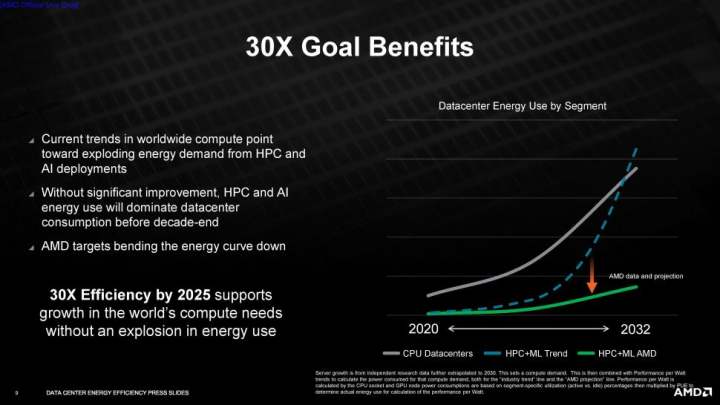
AMDのエネルギー効率目標は、AIトレーニング、気候予測、ゲノミクス、大規模なスーパーコンピューターのシミュレーションなどの機能を実行するアクセラレーション・コンピュート・ノードの処理要件が大幅に増加することを受けたものです。AMDが目標を達成した場合、システムの全体的なエネルギー消費量は、5年間で97%という驚異的な削減が可能になるとします。
AMDの取締役副社長兼CTOであるMark Papermasterは、「プロセッサーのエネルギー効率の向上を達成することは、AMDにとって長期的な設計上の優先事項であり、今回、AIトレーニングやハイパフォーマンス・コンピューティングの展開に適用される当社の高性能CPUとアクセラレーターを使用した最新のコンピュート・ノードに、新たな目標を設定します。これらの非常に重要なセグメントと、大手企業が環境スチュワードシップを強化するための価値提案に焦点を当てたAMDの30倍目標は、これらの分野における業界のエネルギー効率パフォーマンスを、前の5年間と比較して150%上回るものです。」
AMDはすでに、CPUとGPUの設計において豊富な電力効率の改善を模索しており、AMDのZen CPUは実際に性能/ワット比でインテルの最高を上回っているほどです。また、RDNA 2 GPUの消費電力も大幅に改善され、エネルギー効率の面ではNvidia社を圧倒します。改善の一部は、少なくともGPU側では、製造ノードのジャンプに起因します。しかし、製造プロセスを高密度化するためのコストが膨らみ、研究開発期間が長くなる中、AMDは明らかにこれらだけに頼っているわけではありません。
むしろ、3Dキャッシュスタッキング(RDNA 2のチップに採用されたInfinity Cacheは、消費電力を大幅に削減します)などの技術や、ますます効率優先のエンジニアリング・アプローチが必要になるでしょう。また、固定機能のアクセラレーションやソフトウェアの改善も大きな役割を果たすでしょう。AMDがこの目標を達成するためにどのような技術を求めているかはまだわかりませんが、今後4年間でこのような改善を実現できるとAMDが確信していることは心強いことです。
みんなの自作PC
![[70万]RTX3080 12900K 搭載エヴァコラボゲーミングPC(でも正直70万あったら3090Ti乗せてもおさまるから見た目追い求める人以外は3090Ti買ったほうがいい)](https://cdn.jisaku.com/upload/7c/noRgcuZik3ymkn/2400.webp)
